Introduction
When I first started using Unreal, I was surprised by the many ways to represent sets of characters, which include FName, FText, FString, and so on.
After investing some time in the engine and understanding the differences between these representations, I was particularly impressed with the rationale behind the FName – so I decided to adapt it into my engine as FStringID.
The concept, which is broadly recognized as String Interning, is quite straightforward. Given that certain immutable strings recur frequently during the runtime of the executable, we just allocate the entire string once in a table and store its hash to the relevant entry. While this introduces a level of indirection whenever we need to read the string, it can significantly minimize the memory usage, especially for dynamically generated strings.
However, it is important to note that the primary advantage of String Interning is not really memory savings as string literals are stored in the global read-only section of the memory of the program, and certain compilers can eliminate duplicity of strings when String Pooling is enabled. Although in some cases, such as when the same literal is used in different modules or loaded from disk, duplication can still occur.
The real benefit of string interning lies on cheap comparisons. Performing a quick hash check (O(1)) is much more efficient than the worst-case scenario of comparing different-sized standard strings (O(n)). It’s still worth mentioning, though, that in case of hash collisions, the char by char comparison is necessary.
Below is a glimpse at the memory footprint of the FStringID class, which stores only a CRC32 hash. You can learn more about CRC32 here, or you can choose any other hashing algorithm that you might be comfortable with.

To illustrate its usage, let’s consider the scenario where we are working on a shooter simulation in which 2 teams of 5 bots engage in a fight until death. We are tasked with implementing a system that prevents bots of the same team from killing each other. Being discerning engineers, we decide to use a tagging system. This approach allows us to tag all bots in the simulation as either “Team Red” or “Team Blue”. At runtime, we now can easily check their tags to determine the team they belong to.
Clever, isn’t it? Unfortunately, we started working on the tagging system before coming across this post, causing us to make the regrettable decision of using regular string containers, which means allocating memory dynamically for every single tag on every entity. As mentioned, we pride ourselves on being discerning engineers. Hence, after learning about String Interning, we decide to refactor the entire system to start using StringIDs. After running some benchmarks we discover how we went from 95 bytes to just a constant of 27 bytes.
| “Team Red” vs “Team Blue” in a 1vs1 | “Team Red” vs “Team Blue” in a 5vs5 | “Team Red” vs “Team Blue” vs “Team Yellow” in a 10vs10vs10 | |
| Regular String | 19 bytes | 95 bytes | 310 bytes |
| String Interning | 19 bytes (+8 bytes for hashes) | 19 bytes (+8 bytes for hashes) | 31 bytes (+12 bytes for hashes) |
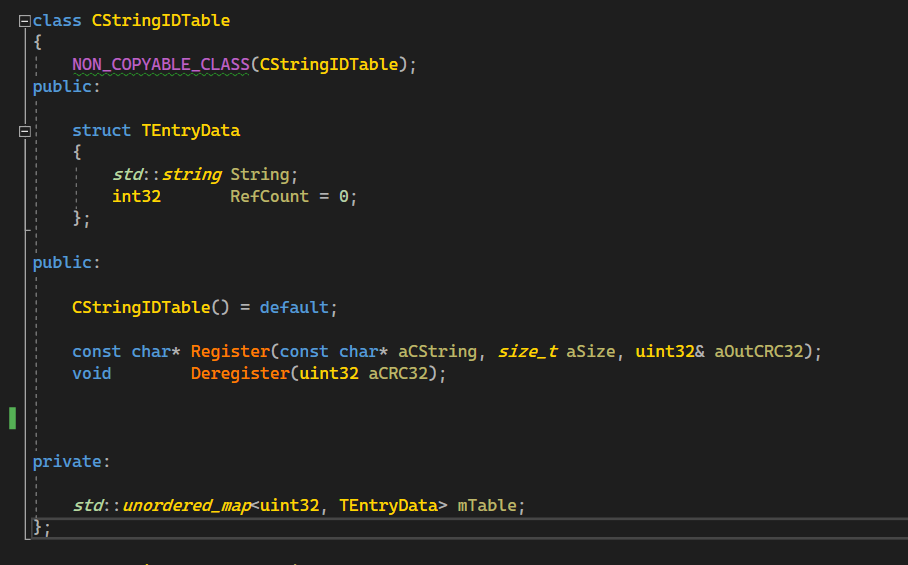
The actual string data would now reside in the CStringIDTable. This table utilizes reference counting to determine when to allocate and deallocate memory buffers for each string:
As with everything in engineering, having good tools to track our systems is a smart decision. Having a panel to monitor the reference counting of the table displaying the count, hash, and memory address of each StringIDEntry can make things a little bit easier.
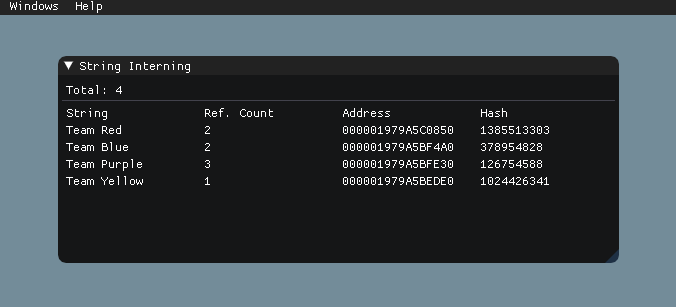
Now, periodically checking the strings to ensure we are consistently taking advantage of the String Interning technique becomes just a click, and, more importantly, it can help avoid falling victim to its potential shortcomings (using String Interning for single-occurrence strings, or discovering your hash algorithm is causing lots of collisions).
Concurrency and More Efficient Comparisons
So far, we have seen an approach that works fine on single-threaded systems, but we want our engine to take advantage of all the cores of our CPU. With the previous implementation, we have two obvious ways to support it:
- Locking: Introduce locks for operations like registering/unregistering, and comparing StringIDs with identical hashes. This is a good option if we do not access the table often, but it can introduce overhead, particularly in scenarios with high-frequency table access.
- Thread-Specific Tables: When we do access the table regularly, it might be better for each thread to allocate its table, therefore bypassing the need for locks. However, it comes at the cost of memory usage, since identical strings may be duplicated across multiple tables.
While both options are fine, there is a third one that consists of limiting the collisions at initialization time, this way we avoid having to access the table when comparing strings, which tends to be the most common operation, therefore reducing the amount of synchronization points and improving efficiency of comparisons. The solution implies replacing the hash map with a handle table.
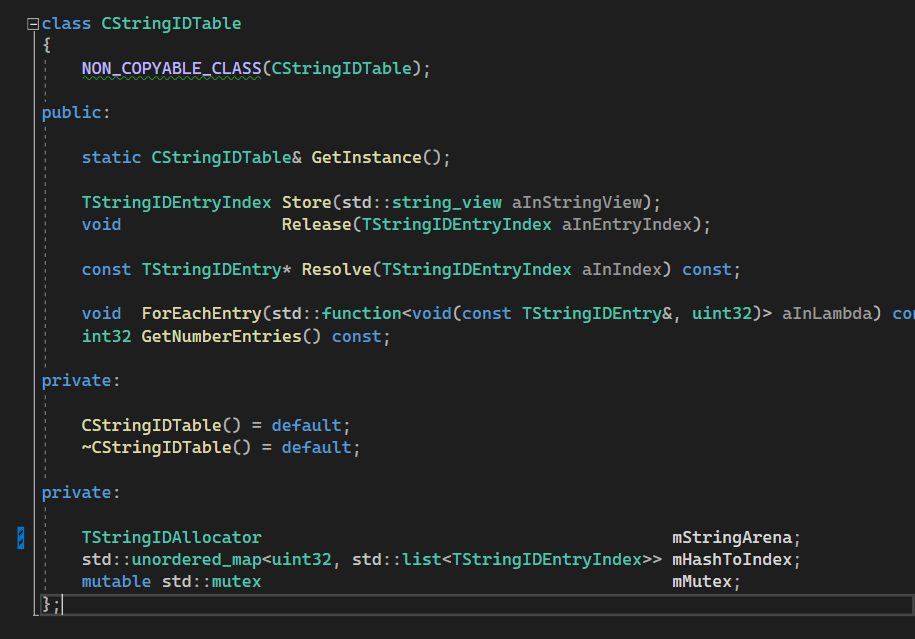
The handle table concept is also straightforward: each FStringID now holds a unique index rather than a hash. This allows for direct index comparisons, bypassing the table entirely. To guarantee that indexes are unique, the HashToIndex container maps each hash to a list of indexes, with each index corresponding to a distinct entry in the StringIDAllocator. This allocator could be a fixed-size array of regular strings for simplicity, where the actual strings are stored.
When adding a new string to the table, we first hash it and check the HashToIndex map for any existing identical hashes. If found, we iterate through the associated index list for an exact string match. A match simply increases the reference count in the StringArena using the existing index. If no match is found, we allocate a new entry for the string also in the StringArena and add this new index to the list.
It is important to keep in mind that with the Index Model having thread-specific is not recommended, as we cannot guarantee the same string to map the same index on each table.
Looking Further
At this point we have covered quite a bit of ground, but there are some aspects worth keeping in mind before implementing anything:
- String Allocator: In the example provided earlier, we have used a compile-time sized array of std::strings to store each literal in the table. While it works fine, it results in a lot of dynamic memory allocations. To avoid this, it is worth considering implementing a string pool, which would improve cache friendliness and, more importantly, mitigate memory fragmentation.
- Removing Entries and Index Duplicity: With the Index model explained above, keep in mind that removing entries from the table is not feasible. This is because eliminating an entry could potentially assign the same index to a new string, causing two FStringID with different strings to have the same index. To avoid this problem, it is recommended to have a model of Index + GenerationID, so that every time we assign a new string to an entry, the Generation ID is incremented. Following this mode, the FStringID would have to store both the Index and the Generation ID.
- Numerical Component: UE’s FName allows for a numerical part to be added when constructing the class. This numerical component is used to differentiate between two FNames with identical strings. The big decision here relies on where to store this number:
- Embed within the FName (StringID class): Increases memory footprint on each instance of the class, but reduces the number of entries in the table.
- Store in the table alongside the associated string: Keeps memory footprint of StringID at the minimum, but could cause an explosion of entries in the table.
- Case Sensitivity vs Insensitivity: Case sensitiveness is really up to the implementation. The decision hinges on how you hash the strings. In case of insensitivity, it is typically the first entry that remains.
And this is the end of my first post of my blog! I would like to thank David Cañadas for helping me improve this entry and for his support, as always.
If you’ve found this blog post useful or if you have any thoughts to share, please don’t hesitate to give me a shout! 🙂
Leave a Reply